한글 비트맵 폰트 출력
- 비트맵 폰트를 언제 사용할까?
- 구현 환경
- 참고하면 좋은 자료
- 비트맵 폰트 출력의 두 가지 방법
- 유니코드 한글 코드를 초성, 중성, 종성으로 나누기
- 초성, 중성, 종성에 따른 ‘벌’ 찾기
- 출력 결과
게임 엔진에 사용하기 위해 비트맵 폰트 출력기를 만들어보았다. 알파벳 사용권에서는 비트맵 폰트를 출력하는 것이 간단하지만 한글을 사용하는 경우에는 한글 자모 분리 등 중간 과정이 필요하므로 조금 복잡하다.
비트맵 폰트를 언제 사용할까?
요즘은 대다수 그래픽 라이브러리가 한글 트루타입 폰트 출력 기능을 지원하기 때문에 사용자가 직접 구현해야 하는 비트맵 폰트를 쓰는 경우는 많지 않은 듯하다. 사실 비트맵 폰트가 트루타입 폰트에 비해 한물 간 기술임은 틀림없다.
하지만 알파벳 사용권에서는 여전히 비트맵 폰트를 많이 활용하고 있다. 출력 방식이 직관적어서 구현하기가 쉽고 트루타입 폰트에 비해 처리속도도 빠르기 때문이다.
전통적으로 비트맵 폰트는 터미널에서 폰트를 출력하는 방식이기도 하다. 그래서 지금도 유명 3D 게임 엔진들의 내부 콘솔 입출력 창에서 종종 비트맵 폰트를 볼 수 있다.
요즘 유행하는 레트로 풍 게임에서도 비트맵 폰트가 많이 사용된다. 고전 게임의 느낌을 살리는데 안티앨리어스 처리를 하지 않은 비트맵 폰트가 딱이기 때문이다. 내가 재미있게 한 작품 중 하나를 꼽자면 Organ Trail이 있다.
한국 주류 온라인 게임 중에는 마비노기가 비트맵 폰트를 사용했다. 아마 아기자기하고 깔끔한 느낌을 살리기 위해 사용한 것 같다. (이 게임에서 사용한 폰트는 크기가 너무 작아서 가독성은 좋지 않다.)
다국어 출력을 지원하지 않는 게임을 한글화 패치 할 때도 비트맵 폰트가 필요할 수 있다. 2003년에 엘더 스크롤스 3: 모로윈드를 팬들이 비공식 한글화 패치할 때 나도 참가했는데 당시 이 게임은 비트맵 폰트만을 지원했다. 그래서 우리는 초성 1벌, 중성 1벌, 종성 1벌로 구성된 한글 비트맵 폰트를 만들어 썼다. 원시적인 방식이고 폰트 가독성도 나빴지만 게임 엔진을 수정하지 않고도 한글 출력을 하는데 성공했다는 것이 의미가 있다. 아쉽게도 내가 참가한 팀에서 완성된 패치를 내지는 못했다.
나는 고전 게임의 느낌을 내기 위해서 비트맵 폰트를 쓸 계획이다. 따라서 내 구현 목표는 도스(MS-DOS) 시절에 널리 사용되던 16x16 픽셀 크기, 초성 8벌, 중성 4벌, 종성 4벌로 구성된 한글 폰트를 출력하는 것이다. 즉, 아래 스크린샷에 나온 것과 같은 형태의 폰트를 출력하는 것이다.
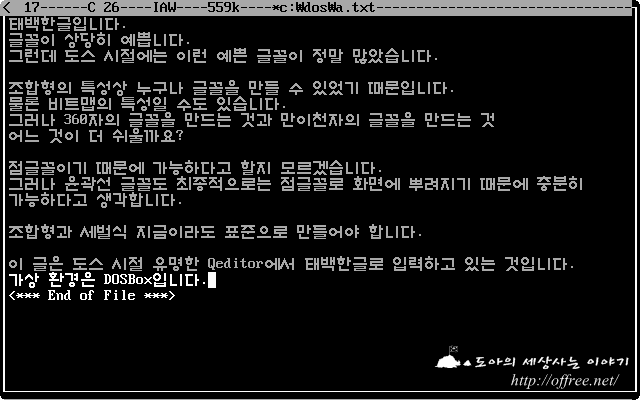
스크린샷 출처: 도아의 세상사는 이야기(http://offree.net/2395)
참고로 위 스크린샷에 서술된 내용은 비트맵 폰트와 조합형 한글 인코딩을 혼동하고 있다. 조합형-완성형 문제는 한글을 코드 테이블에 어떻게 할당할 것인지에 관한 문제이며 폰트 출력방식과는 관련이 없다. 조합형 인코딩이든 완성형 인코딩이든 비트맵 폰트로 출력하는 것이 가능하다. 도스 시절에 완성형 인코딩은 조합형 인코딩과 혼용되었으며 흔히 둘 다 비트맵 폰트 방식으로 출력되었다.
조합형 한글 인코딩 방식에 관해 더 알고 싶다면 이 위키백과 문서를 참고하자.
구현 환경
비트맵 폰트의 블릿팅을 위해 OpenGL(LWJGL)을 이용했다. 나처럼 Clojure-OpenGL 조합을 이용하는 사람은 많지 않을 것 같지만, 한글 자모를 다루는 방식은 공통된 사항이므로 다른 환경에서도 응용할 수 있을 것이다.
편의상 비트벡터 폰트 파일(FNT)을 그대로 쓰지는 않았고, PNG 포맷으로 가공하여 OpenGL의 텍스처링 기능을 활용하는 방식을 택했다.
참고하면 좋은 자료
-
내가 작성한 비트맵 폰트 출력 루틴의 전체 코드는 아래 GitHub 저장소에서 열람할 수 있다.
https://github.com/bakyeono/bitmap-font -
도스용 비트맵 한글 폰트는 다음 페이지에서 구하거나 생성할 수 있다.
http://chem.skku.ac.kr/~wkpark/project/hfed/hfnt.php -
도스용 비트맵 한글 폰트의 출력 방식을 잘 정리한 김성익님의 글. 조합형 코드를 기준으로 쓴 글이지만 8x4x4 폰트의 각 벌의 조합방법 등 여전히 참고할 내용이 있다.
http://mytears.org/resources/doc/Hangul/HANGUL.TXT
비트맵 폰트 출력의 두 가지 방법
단순무식한 방법
한글 비트맵 폰트는 사실 매우 간단한 방식으로 출력하는 것이 가능하다. 알파벳 비트맵 폰트를 구현하는 것이 왜 쉬울까? A-Z까지 코드 배열 순서대로 죽 늘어놓고 하나씩 찍으면 되기 때문이다. 한글도 가-힣까지 한 글자당 하나의 그림으로 모두 그려놓고 하나씩 찍으면 매우 간단하게 처리할 수 있다. 하지만 이렇게 하면 메모리 낭비가 많아 도스 시절에는 사용할 수 없는 방법이었다. 현재에도 별로 추천하고 싶지 않다.
전통적인 방법
도스 시절에 사용한 방법은 초성, 중성, 종성에 해당하는 자모를 제각각 그려놓고 한 글자당 세 개의 자모를 출력하는 방식이다. 글자 코드를 초성, 중성, 종성 자모로 나누는 작업과 자모를 제각각 그리는 수고가 필요하지만 메모리 사용을 줄일 수 있다. 이 글에서는 전통적인 방법을 사용할 것이다.
유니코드 한글 코드를 초성, 중성, 종성으로 나누기
유니코드에서 완성형 한글은 ac00(가)~d7a3(힣)까지 초성, 중성, 종성을 순서대로 조합해 배열한 것이다. 이 순서를 역으로 이용하면 다음과 같은 한글 조합 공식을 얻을 수 있다.
유니코드 한글 조합 공식
완성형 한글 코드 = (((초성번호 * 중성개수) + 중성번호) * 종성개수) + 종성번호 + ac00
여기서 중성의 개수는 21개, 종성의 개수는 28개다.
이 공식을 이용해 다음과 같이 초성, 중성, 종성 분리 함수를 만들 수 있다. (관련 변수명을 지을 때 초성은 head, 중성은 body, 종성은 tail로 표기하였다.)
;; 유니코드 완성형 한글 범위
(def ^:const han-begin 0xac00)
(def ^:const han-end 0xd7a3)
;; 중성의 개수 / 종성의 개수
(def ^:const number-of-bodies 21)
(def ^:const number-of-tails 28)
(def ^:const number-of-bodies*tails
(* number-of-bodies number-of-tails))
;; han-code->head-idx
;; 형식: utf-16-code -> long
;; 완성형 한글 코드를 입력받아 초성의 번호를 반환한다.
(defn han-code->head-idx
[code tail]
(quot (quot (- code han-begin tail)
number-of-tails)
number-of-bodies))
;; han-code->body-idx
;; 형식: utf-16-code -> long
;; 완성형 한글 코드를 입력받아 중성의 번호를 반환한다.
(defn han-code->body-idx
[code tail]
(rem (quot (- code han-begin tail)
number-of-tails)
number-of-bodies))
;; han-code->tail-idx
;; 형식: utf-16-code -> long
;; 완성형 한글 코드를 입력받아 종성의 번호를 반환한다.
(defn han-code->tail-idx
[code]
(rem (unchecked-subtract code han-begin)
number-of-tails))
;; han-code->jamo-idxs
;; 유니코드 완성형 한글 코드값(code)을
;; 초성, 중성, 종성의 각 자모로 분리해 그 번호를 반환한다.
;; 반환값: [초성번호 중성번호 종성번호]
(defn han-code->jamo-idxs
[code]
(let [tail (han-code->tail-idx code)
body (han-code->body-idx code tail)
head (han-code->head-idx code tail)]
[head body tail]))
정의한 han-code->jamo-idxs 함수를 이용하면 다음과 같이 해당하는 초성, 중성, 종성의 순서를 구할 수 있다.
(-> \가 .hashCode han-code->jamo-idxs)
; 반환값: [0 0 0]
(-> \얹 .hashCode han-code->jamo-idxs)
; 반환값: [11 4 5]
(-> \힣 .hashCode han-code->jamo-idxs)
; 반환값: [18 20 27]
초성, 중성, 종성에 따른 ‘벌’ 찾기
초성, 중성, 종성을 분리하는 것으로 한글 비트맵 폰트 출력이 끝나면 좋겠지만 한글 폰트에는 ‘벌’이라는 개념이 있어서 이를 위한 처리가 필요하다.
‘벌’이란?
한글의 자모는 개념적으로는 하나의 자모라 하더라도 다른 자모와의 구성에 따라 형태와 위치가 달라진다. 예를 들어 자음 ‘ㄱ’은 ‘가’에서의 모양, ‘각’에서의 모양, ‘고’에서의 모양, ‘구’에서의 모양, ‘귀’에서의 모양 등이 모두 다르다.
초창기에 한글 폰트 출력을 고민한 사람들은 깔끔한 한글 출력을 위해 자모의 사용 경우에 따라 출력 모양을 어떻게 달리해야 하는지를 연구했다. 그 결과물이 ‘벌’ 개념이다.
도스 시절에 쓰인 8x4x4 폰트에서는 초성의 변화 종류를 8벌, 중성의 변화 종류를 4벌, 종성의 변화 종류를 4벌로 구분하여 그에 맞는 폰트 모양을 그려두고 다른 자모와의 구성에 따라 적절한 모양을 출력하도록 했다.

그림: 한 줄에 한 ‘벌’씩 표현한 8x4x4 이미지 폰트
8x4x4 벌로 구성된 폰트를 한 줄당 하나의 ‘벌’을 넣어 그리면 이런 이미지가 만들어질 것이다. 이 이미지는 실제로 내가 폰트 출력에 사용한 이미지다. 이 이미지에서 해당하는 자모와 벌을 찾아서 각각의 초성, 중성, 종성을 출력하면 조합된 한글이 출력되는 것이다.
그렇다면 알맞은 ‘벌’은 어떻게 찾을 수 있을까?
김성익님의 설명에 따르면 초성, 중성, 종성의 종류에 따른 결합 조건은 다음과 같다.
초성
초성 1벌: 받침없는 ‘ㅏㅐㅑㅒㅓㅔㅕㅖㅣ’ 와 결합
초성 2벌: 받침없는 ‘ㅗㅛㅡ’
초성 3벌: 받침없는 ‘ㅜㅠ’
초성 4벌: 받침없는 ‘ㅘㅙㅚㅢ’
초성 5벌: 받침없는 ‘ㅝㅞㅟ’
초성 6벌: 받침있는 ‘ㅏㅐㅑㅒㅓㅔㅕㅖㅣ’ 와 결합
초성 7벌: 받침있는 ‘ㅗㅛㅜㅠㅡ’
초성 8벌: 받침있는 ‘ㅘㅙㅚㅢㅝㅞㅟ’중성
중성 1벌: 받침없는 ‘ㄱㅋ’ 와 결합
중성 2벌: 받침없는 ‘ㄱㅋ’ 이외의 자음
중성 3벌: 받침있는 ‘ㄱㅋ’ 와 결합
중성 4벌: 받침있는 ‘ㄱㅋ’ 이외의 자음종성
종성 1벌: 중성 ‘ㅏㅑㅘ’ 와 결합
종성 2벌: 중성 ‘ㅓㅕㅚㅝㅟㅢㅣ’
종성 3벌: 중성 ‘ㅐㅒㅔㅖㅙㅞ’
종성 4벌: 중성 ‘ㅗㅛㅜㅠㅡ’
이 결합 조건은 클로저의 해시맵 자료구조로 바로 변환이 가능하다.
;; make-suit-matchers
;; make-suit-dic
;; '벌' 테이블 생성을 위한 편의 함수
(defn- make-suit-matchers
[v ks jamo->idx]
(for [k ks] [(jamo->idx k) v]))
(defn- make-suit-dic
[v-kss jamo->idx]
(into {} (apply
concat
(for [[v ks] v-kss]
(make-suit-matchers v ks jamo->idx)))))
;; suit-of-head-on-body-without-tail
;; 중성번호에 따른 초성의 벌 (종성이 없을 때)
(def ^:const suit-of-head-on-body-without-tail
(make-suit-dic
[[1 [\ㅏ \ㅐ \ㅑ \ㅒ \ㅓ \ㅔ \ㅕ \ㅖ \ㅣ]]
[2 [\ㅗ \ㅛ \ㅡ]]
[3 [\ㅜ \ㅠ]]
[4 [\ㅘ \ㅙ \ㅚ \ㅢ]]
[5 [\ㅝ \ㅞ \ㅟ]]]
body->body-idx))
;; suit-of-head-on-body-with-tail
;; 중성번호에 따른 초성의 벌 (종성이 있을 때)
(def ^:const suit-of-head-on-body-with-tail
(make-suit-dic
[[6 [\ㅏ \ㅐ \ㅑ \ㅒ \ㅓ \ㅔ \ㅕ \ㅖ \ㅣ]]
[7 [\ㅗ \ㅛ \ㅜ \ㅠ \ㅡ]]
[8 [\ㅘ \ㅙ \ㅚ \ㅝ \ㅞ \ㅟ \ㅢ]]]
body->body-idx))
;; suit-of-body-on-head-without-tail
;; 초성번호에 따른 중성의 벌 (종성이 없을 때)
(def ^:const suit-of-body-on-head-without-tail
(make-suit-dic
[[1 [\ㄱ \ㅋ]]
[2 [\ㄲ \ㄴ \ㄷ \ㄸ \ㄹ \ㅁ \ㅂ \ㅃ
\ㅅ \ㅆ \ㅇ \ㅈ \ㅉ \ㅊ \ㅌ \ㅍ \ㅎ]]]
head->head-idx))
;; suit-of-body-on-head-with-tail
;; 초성번호에 따른 중성의 벌 (종성이 있을 때)
(def ^:const suit-of-body-on-head-with-tail
(make-suit-dic
[[3 [\ㄱ \ㅋ]]
[4 [\ㄲ \ㄴ \ㄷ \ㄸ \ㄹ \ㅁ \ㅂ \ㅃ \ㅅ \ㅆ
\ㅇ \ㅈ \ㅉ \ㅊ \ㅌ \ㅍ \ㅎ]]]
head->head-idx))
;; suit-of-tail-on-body
;; 중성번호에 따른 종성의 벌
(def ^:const suit-of-tail-on-body
(make-suit-dic
[[1 [\ㅏ \ㅑ \ㅘ]]
[2 [\ㅓ \ㅕ \ㅚ \ㅝ \ㅟ \ㅢ \ㅣ]]
[3 [\ㅐ \ㅒ \ㅔ \ㅖ \ㅙ \ㅞ]]
[4 [\ㅗ \ㅛ \ㅜ \ㅠ \ㅡ]]]
body->body-idx))
결합 조건의 해시맵을 이용하면 쉽게 변환 함수를 만들 수 있다.
;; get-suit-of-head
;; 중성번호와 종성번호를 입력받아,
;; 이에 해당하는 초성의 벌을 반환한다.
(defn get-suit-of-head
[body tail]
(if (zero? tail)
(suit-of-head-on-body-without-tail body)
(suit-of-head-on-body-with-tail body)))
;; get-suit-of-body
;; 초성번호와 종성번호를 입력받아,
;; 이에 해당하는 중성의 벌을 반환한다.
(defn get-suit-of-body
[head tail]
(if (zero? tail)
(suit-of-body-on-head-without-tail head)
(suit-of-body-on-head-with-tail head)))
;; get-suit-of-tail
;; 중성번호를 입력받아,
;; 해당하는 종성의 벌을 반환한다.
(defn get-suit-of-tail
[body]
(suit-of-tail-on-body body))
;; jamo-idxs->jamo-suits
;; [초성번호 중성번호 종성번호]를 입력받아,
;; 해당하는 벌을 [초성벌 중성벌 종성벌] 형태로 반환한다.
(defn jamo-idxs->jamo-suits
[[head body tail]]
[(get-suit-of-head body tail)
(get-suit-of-body head tail)
(get-suit-of-tail body)])
jamo-idxs->jamo-suits 함수에 초성, 중성, 종성 자모를 전달하면 초성, 중성 종성의 ‘벌’을 구할 수 있다.
(-> \가 .hashCode han-code->jamo-idxs jamo-idxs->jamo-suits)
; 반환값: [1 1 1]
(-> \각 .hashCode han-code->jamo-idxs jamo-idxs->jamo-suits)
; 반환값: [6 3 1]
(-> \고 .hashCode han-code->jamo-idxs jamo-idxs->jamo-suits)
; 반환값: [2 1 4]
(-> \구 .hashCode han-code->jamo-idxs jamo-idxs->jamo-suits)
; 반환값: [3 1 4]
이제 하나의 글자 코드가 있을 때 분리된 초성, 중성, 종성 자모와 각 자모의 ‘벌’을 구할 수 있으므로 8x4x4 한글 비트맵 폰트를 출력할 수 있다. 출력 과정은 단순히 이미지를 타일링 및 블릿팅 하는 것일 뿐이며 개발 환경에 맞춰 구현해야 하므로 생략한다. 내가 OpenGL 용으로 구현한 코드를 보고 싶다면 GitHub 저장소에서 볼 수 있다.
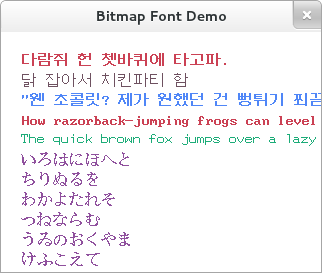
출력 결과
아래 스크린샷은 위의 8x4x4벌로 구성된 16x16 크기의 이미지 폰트를 출력한 것이다. (일본 문자 폰트와 아스키 폰트도 함께 출력해 보았다.)